Method Overview
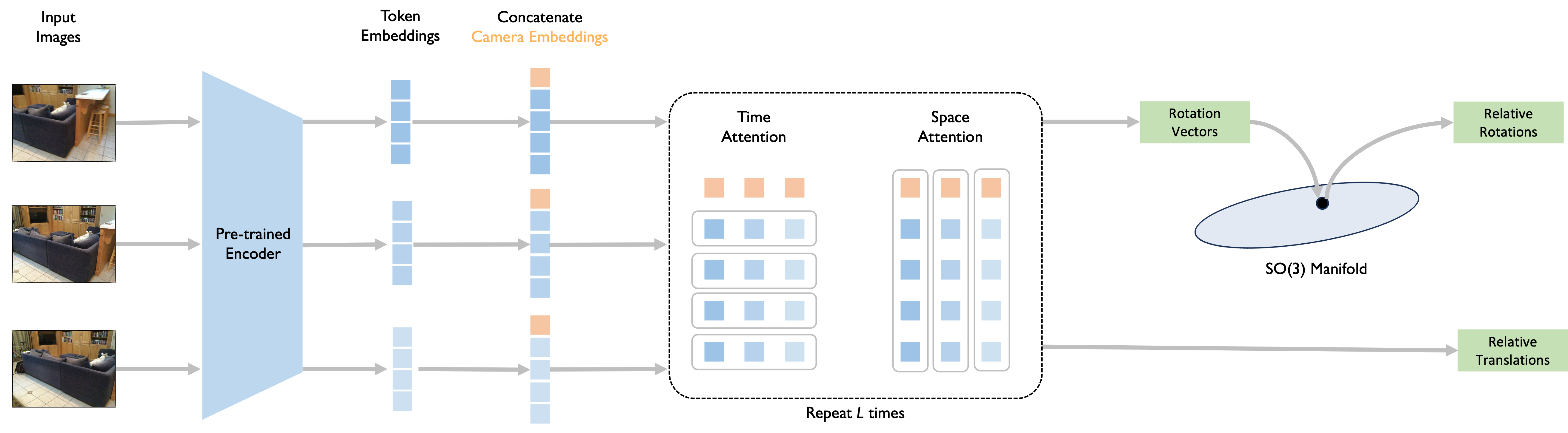
VoT Architecture. Given multiple input frames, a frozen image encoder extracts per-image token embeddings. Camera embeddings are then concatenated to aggregate the information for camera pose estimation. The embeddings are decoded by L repeating decoder blocks with temporal and spatial attention modules. The rotations are projected onto the SO(3) manifold to ensure valid relative rotations.