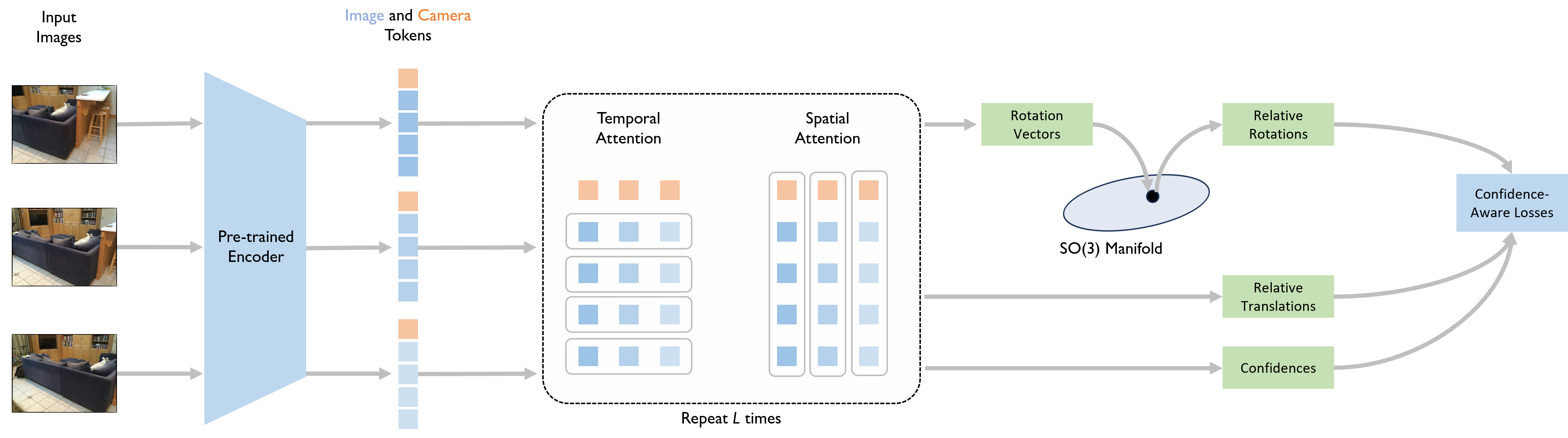
Method Overview

Fast Visual Odometry Pipeline. The metric camera trajectory is derived by passing overlapping image windows through a transformer that estimates relative camera poses and their confidence scores. Subsequently, the inference module integrates these pose and confidence estimates into a unified trajectory. FVO is almost 2 times faster than the fastest baseline on commodity hardware. Moreover, our method does not rely on camera parameters or test-time optimization.